AI Document Processing , AI Enablement For Finance Teams , Google Sheets Automation , Legal Documents Processing Flows , Operationalize AI For Business
Looking for the best way to extract table data from PDFs in 2026? Discover 5 tools—including Zenphi + Gemini—to automate data extraction and send it to your CRM through Google Sheets.
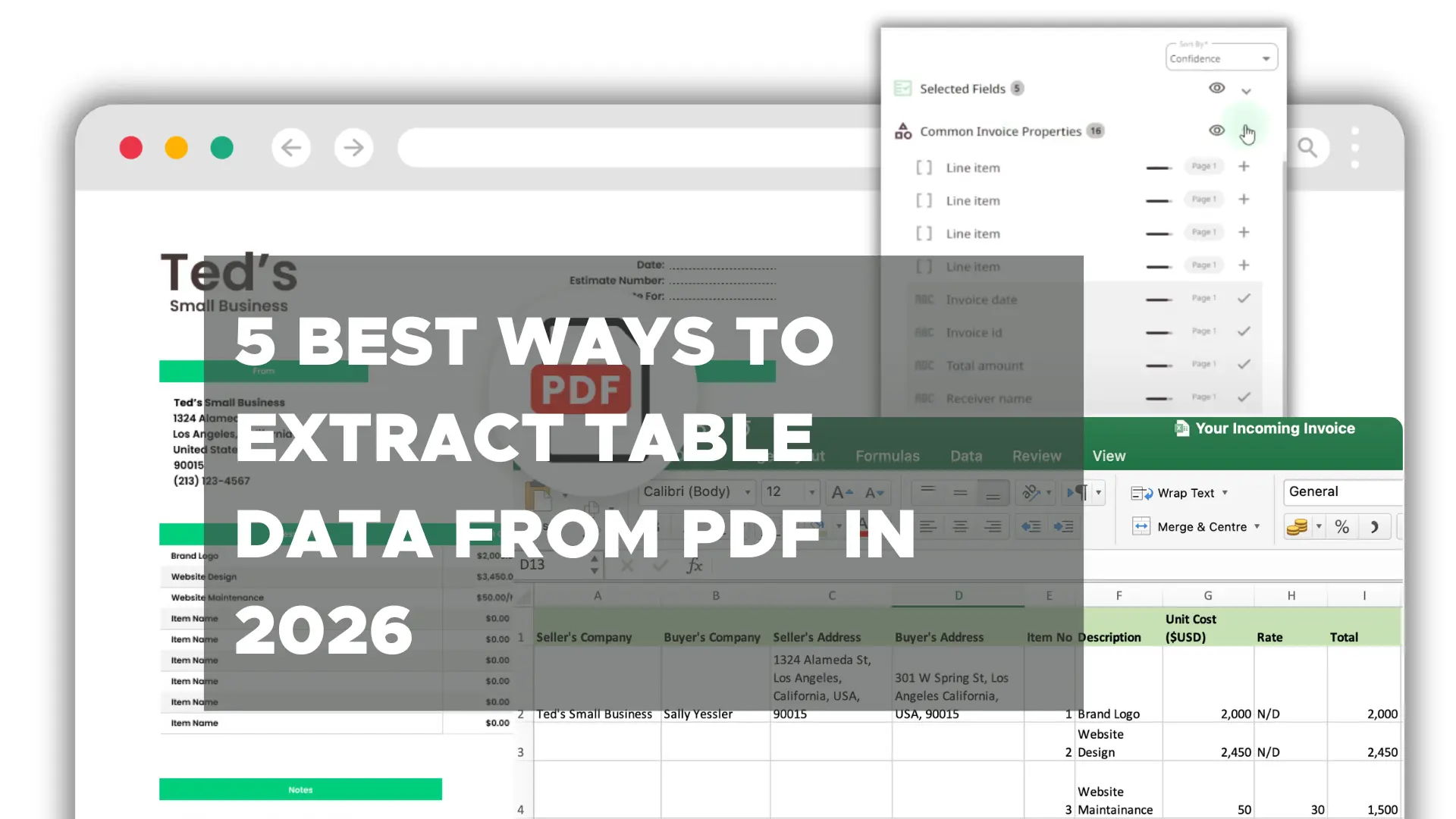
Table of Contents
Extracting table data from PDFs—especially scanned or image-based ones—has traditionally been one of the most frustrating data challenges in business operations. You need those line items, quantities, and totals out of a PDF invoice or report and into a system like Google Sheets, QuickBooks, or your CRM. But copy-pasting doesn’t scale, and most OCR tools fall short.
The good news? In 2026, smarter tools are finally making this process fast, reliable, and fully automatable. We collected the 5 best ways to extract table data from PDF files (and send it directly to your CRM or database).
But first, let’s look at the use cases of when exactly would you need to extract table data from PDF.
Use Cases for Extracting Table Data from PDFs to CRMs and Other Systems
Here are just a few real-world use cases that benefit from extracting data from PDF automation:
- Invoice Processing: Automatically extract line items from vendor invoices and log them in Google Sheets, QuickBooks, or NetSuite.
- Order Management: Capture customer purchase data from PDFs and sync it to your CRM or fulfillment system.
- Shipping & Logistics: Extract delivery details from packing slips and update your internal tracking sheet or supply chain dashboard.
- Expense Tracking: Pull expense data from receipts and populate an expense approval workflow.
- Data Aggregation: Use extracted table data to fuel dashboards, forecasts, or compliance reports.
The #1 PDF Data Extraction Solutions For Teams Using Google Workspace
Zenphi is the best tool for teams using Google Workspace and looking for automation of their PDF data extraction workflows. From inbox automation and email monitoring to assigning tasks to the team members, Zenphi allows to embed PDF data extraction into end-to-end business process automations.
Five Tools For Automated Table Data Extraction From PDF
1. Zenphi + Google Gemini: AI-Powered Automation For Companies Using Google Workspace Tools
If you’re using Google Workspace and relevant tools like Google Sheets, this is the most powerful no-code options available.
With Zenphi, you can build a workflow that automatically:
- Reads PDF files from incoming emails, Drive, or form uploads
- Uses Google Gemini AI to detect and extract table structures
- Uses Google Gemini AI to detect and extract table structures
- Triggers additional steps like alerts, approvals, or email summaries
Zenphi is absolutely unbeatable solution for lean Finance and Ops teams automating invoice processing, as well as Customer Success workflows or Sales Ops processing order PDFs. Also widely used by HR and Finance to extract data from payslips and store in a designated database.
The best part about Zenphi is that you don’t have to be technical to set up the automation.
Here’s a 5 min tutorial that explains how you can do it in no time. The very basic automation is built for extracting table data from PDF into structured format of Google Sheets. You can replace Google Sheets with your CRM — HubSpot, Salesforce, Monday.com — or any application that allows API connection. Before building an API connection, though, check if Zenphi already has a pre-built integration with your app.
2. Tabula – Open-Source PDF Table Extractor

Tabula is a free, open-source tool built specifically to extract tables from PDFs. It lets you manually select the region on the PDF where the table appears. It is great for batch exports, and obviously a big pro is that it’s a free tool.
However, Tabula doesn’t work with scanned/image-based PDFs and doesn’t allows full-scale workflow automations — you’ll have to upload your PDFs manually every time, then download the output files, then import them into your CRM or other app. No work-arounds.
Also, because Tabula is open source, it is only used by the teams that are not very concerned about compliance and audit trials. Once again, if you’re looking for a HIPAA-compliant automation (for example, automation for Healthcare), Zenphi would be your best choice.
3. Adobe Acrobat Pro + Export to Excel
If you’re looking for a desktop solution and need table data extraction to Excel, Adobe Acrobat Pro has long offered the ability to export table data from PDFs into this popular Microsoft app. It works well with native digital PDFs and preserves formatting for simple tables.
However, just like Tabula, it might struggle with scanned/image-based PDFs, has no CRM integrations and still assumes a lot of manual work for file uploads and output imports. If your team has a very limited automation needs and you need just a one-off conversion, Adobe Acrobat Pro is a great tool for you.
Ready to embed PDF data extraction in a company-wide workflow?
Weather you’re looking for an invoice processing solution or need a HIPAA-compliant healthcare automation tool that would extract medical records, Zenphi will be a game changer for you. Book a call with Zenphi automation expert to get access to special prices.
4. Power Automate + AI Builder (Microsoft)
Microsoft Power Automate users can tap into AI Builder to extract table data from PDFs and route it into Dynamics 365, Excel, or other apps.
However, this powerful solution doesn’t come in free — it requires Power Platform licensing. Also, in general it provides very limited control over table parsing and cleanup. For example, you submitted multiple PDFs as a part of your inbox automation workflow. However, the output doesn’t look right. Power Automate’s AI Builder doesn’t allow you to change anything in the way data parsing works (retrain the model) or clean up the tables. Your outputs will be as they are — basically, take it or leave it.
If being in control over your data and the way it is processed is important for you, we recommend look into Zenphi once again — it’s a powerful alternative to Power Automate, and not just for Google but also for Microsoft users.
5. Amazon Textract (via API)
This a great solution. It offers a way to build necessary automation and never struggles with images or scans — no wonder, as it has a powerful Amazon-driven OCR backend.
However, the downsides are obvious as well. This solution is useful mainly for developers — as table data extraction leads to structured JSON outputs. Also, it requires AWS setup and development skills — the solution has no visual interface or workflow engine, so your Finance or HR team would be completely confused about necessary steps and actions.
Read More On Extracting Data From PDF Automations
Three Way Invoice Matching Automation
Learn how to automate one of the most important processes in accounts payable — 3 way invoice matching, using Google Sheets.
Process PDF With AI Faster
All you need to know about AI-driven data extraction from PDF: why do you need it, the use cases and tools you might use.
Automated Accounts Payable Video Guide
A step-by-step guide on how to build automated accounts payable process using tools that you’re likely already using — like Google Sheets and Gmail. A detailed video tutorial included.
Two-Way Invoice Matching
Learn what 2-way invoice matching is, why it’s critical for finance teams, and how automation tools like Zenphi can simplify and scale this process.
Success Story: 90% Cost Reduction
Case Study: children camp using AI workflow automation in Google Workspace to enhance safety and save time
Three Way Invoice Matching Automation
Process PDF With AI Faster
Automated Accounts Payable Video Guide
Two-Ways Invoice Matching Guide
Success Story: 2 Weeks Saved

